
Estimados todos, ¿qué tal? Espero que todo esté yendo muy bien. Les comento que este es el comienzo, sí, ¿el comienzo de qué? El inicio de una aventura hacia uno de los análisis más usados en estadística. La regresión lineal. Antes que nada, les cuento que este es un previo, porque ese análisis que les cuento es la regresión lineal múltiple. Pero para llegar a ella, previamente tenemos que hacer la más simple de sus versiones.
En este, caso, no pondré cuál es el objetivo de este post al comienzo, los valientes lectores ya deben imaginar cuál debe ser el propósito de este capítulo de Stats SOS. Para este post, y a manera de comenzar un nuevo tema y hacer pequeños cambios pondré el objetivo al final.
La regresión lineal simple, como su nombre lo dice es un análisis lineal. ¿qué significa esto? Que busca encontrar si existe una relación entre una variable y otra. Ahora, los valientes lectores que conocen la correlación de pearson (pueden encontrarla aquí), me dirán que esto suena igual. Bueno, en cierta manera la regresión lineal simple y la correlación de pearson son análisis muy parecidos y son parte de una misma familia. La gran diferencia entre una y otra es que la correlación de Pearson busca la relación entre dos variables, mientras que la regresión busca ver cómo una variable explica a otra variable. Aparte, al igual que la correlación, la regresión lineal simple utiliza variables de intervalo y no puede utilizarse con otros tipos debido a que es un análisis lineal. Recuerden, valientes lectores, siempre pueden ir a post anteriores para revisar algo que no recuerden. Para este caso, este post los puede ayudar a recordar qué es una variable de intervalo.
¿Está todo bien? ¿Suena raro y extraño? No hay ningún problema, no se angustien ni se preocupen. Vamos a un ejemplo, los maravillosos ejemplos siempre son excelentes para nuestro aprendizaje.
En nuestras labores cotidianas (ya sea estudiando algo o trabajando en algo), nos hemos percatado que tener un grupo de amigos o amables colegas en el trabajo nos permite relajarnos y a su vez hacer que el estrés descienda. Sin embargo, esta es una simple deducción y como investigadores, es importante que probemos científicamente si es que efectivamente esto se da en la realidad. Si lo haces al ojo, terminas con un ojo morado :).
Por ello, un grupo de investigadores deciden hacer una pequeña investigación. Para ella, recogen información de 270 jóvenes sobre estrés (variable A) y soporte social (variable B) y buscan conocer si es que el soporte social puede explicar el estrés. Para ello, miden las dos variables con dos cuestionario y sacan los promedios de puntajes de cada uno. En ese caso, tanto la variable A, así como la variable B son de intervalo. Recuerden, este post los puede ayudar para recodar qué es una variable de intervalo.
¡Excelente! Luego de ingresar todos los datos, corremos los análisis. ¡Espera! ¿Cómo se corren los análisis? ¡Pues muy sencillo!
En este caso, con el SPSS se debe seguir la siguiente ruta:
Analizar/regresión/lineales/
Para este caso, como queremos saber si el soporte social puede explicar el estrés, ponemos como variable dependiente, estrés y en variable independiente soporte social. Luego de ello ponemos aceptar. ¡Aquí vamos!
¡Muy bien! Ahora que el SPSS proceso todos nuestros datos, esto ocurrió: ¿Están listos? ¿Preparados? Nos mostró tres tablas básicas. Para este post solo pondré las tablas básicas pero para siguientes publicaciones esto se irá poniendo más y más complejo. Pero con calma, estoy seguro que todo irá muy bien.
Tabla 1
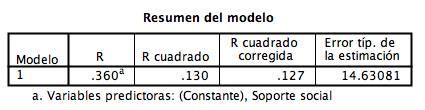
Esta tabla lo que nos muestra básicamente es cuán relacionadas están estas variables. En este caso, la tabla no pone la dirección (directa o inversa) de la relación entre soporte social y estrés. Lo único que hace es poner cuán relacionadas están las variables. Esto es muy similar a una correlación de Pearson, los que no recuerdan que es esto pueden ir a este post.
¡Muy bien! En este caso, la R significa la relación entre soporte social y estrés, en este caso nos dice que hay una importante relación (.36) entre las dos variables. Los que no recuerdan qué era una relación entre dos variables, ¡no hay problema! este post puede ser de mucha utilidad.
Por otro lado, la R cuadrado es como su nombre lo dice, la relación (R) elevada al cuadrado. El R cuadrado, es la proporción de varianza explicada de estrés por soporte social. En otras palabras, cuánto los puntajes de soporte social explican los puntajes de estrés. Por el momento, solo hablaremos de estos dos análisis, los que tienen curiosidad de saber qué es la R cuadrado corregida, siempre pueden dejar un comentario en la sección posterior y encantado de ayudar. De todos modos, cuando veamos regresión múltiple la R cuadrado corregida tomará bastante importancia.
Tabla 2

Esta tabla de ANOVA (¿les suena conocida? a los que no, este post puede ayudarlos a identificar rápidamente la misma). Nos menciona si es que nuestro modelo que busca explicar el estrés utilizando el soporte social es significativo o no. Mientras más grande sea la F hay más probabilidad que nuestro modelo sea significativo. ¿Por qué? Porque mientras más grande es la F hay menor probabilidad que la explicación de estrés por soporte social se de por el azar o algún motivo desconocido. En este caso, vemos que el modelo es significativo ya que es menor a .05. Los que no recuerdan qué significa esto, ¡no hay ningún problema! Este post los puede ayudar a recordar a qué se refiere una significación.
Tabla 3
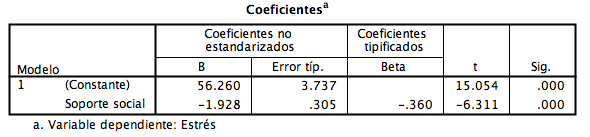
Finalmente, esta tabla nos muestra nuestro modelo de regresión lineal simple pero al detalle. En este caso podemos ver dos lineas, de datos. La primera que se refiere a la constante y la segunda directamente al soporte social. En este caso, no hablaremos mucho de la constante, pero lo que si mencionaremos es que la constante se refiere a los valores que toma la variable que queremos explicar (en este caso estrés) cuando nuestra variable explicativa o predictiva (soporte social) es igual a 0. ¡Muy bien! Dicho esto, sigamos avanzando. Vamos a saltar la línea de la constante y nos iremos directamente a la línea que nos habla del soporte social. Los coeficientes no estandarizados, miden el cambio entre la variable independiente (soporte social) y la variable dependiente (estrés). ¿Qué dice este análisis? Para este caso, cada vez que se incrementa un punto en soporte social, el estrés baja en 1.928 (porque si ven la tabla 3, el número tiene un signo negativo).
Por otro lado, el coeficiente tipificado, nos menciona la misma información con una gran diferencia. El coeficiente tipificado mide el cambio o cuánto explica soporte social al estrés, con valores que van desde -1 a 1 (así como una correlación). Este coeficiente también es llamado coeficiente estandarizado, porque los puntajes se han estandarizado (o convertidos) para solo tener valores entre -1 y 1. ¿Por qué es útil esto? Cuando se tiene varias variables (regresión múltiple) se puede saber cuál de las variables de nuestro modelo explica mejor la variable que queremos explicar. Entiendo que ahora esto puede ser poco claro, pero cuando veamos regresiones múltiples verán que esto se vuelve mucho más claro ¡Se los prometo!
De todos modos, el coeficiente tipificado, tiene una particularidad bien interesante en la regresión lineal simple. Este valor, es idéntico al que obtendríamos si hiciéramos una correlación de Pearson entre Soporte social y estrés. Si no me creen, ¡no hay problema! Si ven a continuación (tabla 4), observarán un análisis de correlación de las dos variables que mencioné y verán que estrés y soporte social tienen una relación de -.36 que es exactamente igual al coeficiente tipificado de la tabla 3 en la línea de soporte social.
¿Qué significa esto? Que hay una relación inversa (ver post de correlaciones), entre los puntajes de soporte social y los puntajes de estrés. En términos de regresión, el soporte social explica el estrés en .360 y ha mayor soporte social menor estrés.
Finalmente, verán que estos valores son significativos porque son menores a 0.05 (en las tablas 3 y 4 aparecen valores de .000, en otras palabras, valores muy pequeños). Ello implica que está relación es significativa (ver post).
Tabla 4

¡Muy bien! Esto sería todo por hoy. El objetivo de este post fue describir de manera sencilla, ¿qué es una regresión simple? Un tema importantísimo de tomar en cuenta, es que si bien hemos utilizado la palabra “explicar” para referirnos a la regresión, no es apropiado hablar de causalidad aquí. Es mejor, y más cauteloso hablar de relación en lugar de causalidad, pero por temas didácticos es que hemos usado la palabra explicar. Para lograr encontrar causalidad es necesario utilizar diferentes diseños de investigación como por ejemplo el experimental.
Para la siguiente aventura de Stats SOS, veremos los principios que se deben seguir para hacer una eficiente y precisa regresión lineal multiple. En el siguiente post verán que haré mención de un buen amigo y seguidor del blog que quería ser parte del blog y como él siempre me ha dado apoyo entonces le concedí el pedido. Dudo que mi novia se ponga celosa de ello, así que no hay problema :). Recuerden que siempre pueden dejar un maravilloso comentario en la parte de comentarios.
¡Espero que todos tengan una excelente semana y buenas vibras para todos!

Muchas gracias por la información. Tengo una consulta, el resultado del análisis indica que las dos variables están relacionadas, pero ¿cómo saber cuál es la dirección de esa relación? ¡Saludos!
LikeLike
Estimada Silvia,
Gracias por escribir en los comentarios. A ver dos cosas:
1) Si por dirección te refieres si es que es inversa o directa la relación, habrá un signo que te lo pueda decir. Si el signo es negativo, entonces la dirección es inversa, si es positivo es directa. En el ejemplo la dirección es inversa. A mayor soporte social, menor estrés.
2) Si por dirección te refieres a quién afecta a quién. La variable independiente (Soporte social) influye o predice a la variable dependiente (Estrés). En ese caso, la dirección es que la variable que predice (o predictora, soporte social) “explica” al estrés.
Esta última idea es la gran diferencia con una correlación de Pearson donde no se asume una dirección sino más bien que están relacionadas.
Espero que te haya ayudado, si tienes más observaciones encantado de responder.
¡Buenas vibras!
LikeLike
Estimado Juan Carlos,
Muchas gracias por la respuesta. Mi consulta ha sido respondida en el punto 2, en el que mencionas cuál de las variables es la que influye, me queda clara la diferencia con la correlación de Pearson. Otra consulta, ¿es lo mismo que decir causalidad? En el ejemplo ¿se podría afirmar que la variable soporte social causa o provoca el estrés? Gracias nuevamente.
LikeLike
Estimada Silvia,
Me alegra haber respondido tu inquietud. La verdad que yo no diría “causa”, porque ahí entrarías en un problema complicado. Si tuviera que usar un adjetivo en español quizás “predice” o “explica” podría ser una mejor opción.
La casualidad se puede conseguir con análisis mucho más complejos e incluso con otros diseños metodológicos pero una regresión no permite afirmar causalidad.
Espero te sirva
¡Buenas vibras!
LikeLike
Pingback: Gonzalo apoya la aditividad: Los 4 supuestos de la regresion lineal | Stats SOS
Pingback: Un día llegó la regresión múltiple | Stats SOS
Hola! gracias por este post, realmente ayuda y en general el blog es de gran ayuda.
quería saber existe alguna manera en q el spss calcule el r2 para cada item de mi prueba o tendría q hacerlo de manera manual?
quiero hacer esto porque quiero replicar un estudio q lei recientemente y en este paper han calculado el r2 para cada item de la prueba q estoy usando… como hago esto?
LikeLike
Hola Esther,
Muchas gracias por escribir a Stats SOS. La verdad que nunca he intentado calcular el R2 para la correlación ítem, puntaje total de una prueba. Sin embargo, esto no es complicado hay tres maneras de hacerlo.
1) Puedes hacer una regresión lineal simple de cada ítem con el puntaje total de la prueba. Uno por uno hasta tenerlos todos y ahí te da el R2. Aquí en Stats SOS hay un post sobre esto :).
2) Puedes hacer una correlación de los puntajes de cada ítem con los puntajes de la prueba total y esos valores elevarlos al cuadrado. Esto te da lo que llaman también coeficiente de determinación o el famoso r2. Esta vendría a ser la proporción de varianza explicada de los puntajes totales de la prueba por los puntajes del ítem.
3) Puedes pedirle la confiabilidad con el estadístico de alfa de cronbach (ver post), ahí el SPSS te arroja la correlación puntajes del ítem con los puntajes totales de la prueba. Si esos valores los elevas al cuadrado te sale el R2.
Estos métodos son equivalentes, sin embargo yo escogería el segundo porque no es muy claro como el SPSS calcula los puntajes totales de una prueba (problema con la opción 3). Aparte, la opción 1 puede llegar a ser algo tediosa.
¡Espero que todo salga excelente!
¡Muchos éxitos!
LikeLike
Hola Juan, la verdad tus aportes son muy útiles. Para mi la estadística aún es un poco difícil, pero no por ello deja de ser retadora e interesante.
justamente el objetivo de hallar el r2 para cada item de la prueba es que quiero medir la varianza explicada de cada item en la varianza del puntaje total de la prueba (no sé si hasta aquí estoy bien o más o menos bien?). Leyendo un poco más el paper, me di con la sorpresa que para calcular el r2 de la prueba q estoy usando, se había hecho una regresión múltiple (aún no he leido tu blog de este tema, pero sí lo haré …). Sin embargo, yo también había pensado usar la opción 1 que mencionas, es decir hacer una regresión lineal simple de cada ítem con el puntaje total (la verdad me sorprendiste al saber que había 3 formas de calcular el r2
🙂 )… pero ahora q sé q han hecho una regresión multiple, me preguntaba si es lo mismo hallar el r2 haciendo regresiones lineales simples entre cada item y el puntaje total o debiera hacer una regresion multiple y hallar el r2 para cada item… Help, hasta aquí, ya estoy un poco confundida sobretodo porque la regresión múltiple no necesariamente es un campo que maneje
LikeLike
Estimada Esther,
Muchas gracias por escribir nuevamente a Stats SOS. Me alegra que la página esté siendo útil para ti.
Aquí te dejo el post sobre regresión múltiple. http://statssos.net/2015/05/12/un-dia-llego-la-regresion-multiple/
En realidad te recomiendo hacer solo una regresión múltiple con todos los ítems. No es adecuado hacer varias regresiones lineales simples porque el error crece enormemente. ¿Por qué se da esto? Porque cada análisis tiene su propio error de estimación. En ese caso, siempre es mejor hacer un análisis que pueda englobar todo en lugar de varios análisis que solo se enfoque en ciertas partes.
En general, el riesgo de hacer múltiple análisis es que el error tipo 1 crezca enormemente. Aquí te dejo el post de tipos de errores que podría ayudarte también.
http://statssos.net/2014/11/24/errores-existian-errores-en-estadistica/
Finalmente, lo que te podría recomendar es poner todos los ítems com variables independientes y el puntaje total como variable dependiente. Sin embargo, a esta técnica le veo un pero, que es el problema de multicolinealidad. Si hay una alta relación entre ítems entonces habrá multicolinealidad y tu regresión múltiple estará sesgada.
Te recomiendo ir a este post que también podría serte de ayuda.
http://statssos.net/2015/03/18/gonzalo-apoya-la-aditividad-los-4-supuestos-de-la-regresion-lineal/
¡Muchos éxitos! ¡Espero que todo salga bien! Como siempre, muchas gracias por escribir a Stats SOS.
LikeLike
Muchas gracias Juan, una consulta al respecto. Acabo de terminar de leer tu post de regresión lineal multiple y hay muchas cosas q me quedaran más claras. Mi duda es q como quiero hallar el r2 entre cada item y el puntaje total, al hacer una regresion multiple, el spss solo me arroja un r2… apreciaré tus comentarios
LikeLike
Estimada Esther,
Muchas gracias por escribir en Stats SOS. Sí, el SPSS te arroja entre otras cosas un R2 que se puede encontrar en la primera tabla. Así que no hay ningún problema.
¡Muchos éxitos!
LikeLike
otra opcion q estaba pensando es hacer la regresion lineal multiple pero usando el método de pasos sucesivos, lo malo es q a medido q añado variables independientes, el r y r2 aumenta… tambien apreciaré tus comentarios al respecto
LikeLike
Estimada Esther,
Nuevamente te agradezco tu activa participación en el blog. Por supuesto, también puedes hacer el método de pasos sucesivos, en general cuando uno hace una regresión lineal múltiple suele meter (o sacar) una variable a la vez. Entonces, seguir el método de pasos sucesivos sí es una muy buena opción.
¡Muchos éxitos!
LikeLike
Hola! Cuál es el n(cantidad de casos) mínimo para hacer una regresión?
LikeLike
Hola,
Muchas gracias por escribir a Stats SOS. De acuerdo con el G*Power, para una regresión lineal simple con una variable independiente necesitas como mínimo 89 casos y para una regresión lineal con dos variables independientes 107 casos.
Ojalá todo salga bien.
¡Muchos éxitos!
LikeLike
Excelente juan Carlos, gracias por la explicación, precisa ahora que estoy en análisis de resultados de mi tesis!!
LikeLike
Estimado Luis Enrique,
Muchas gracias por escribir a Stats SOS, me alegra que esté siendo de ayuda.
¡Muchos éxitos!
LikeLike
hola Juan, la variable dependiente en la regresión puede ser un solo item? gracias
LikeLike
Hola,
Muchas gracias por escribir a Stats SOS. En términos estrictos no se puede a menos que sea un ítem con una escala likert de por lo menos 7 opciones.
De todos modos, hay gente que intenta hacer una regresión con un ítem que está compuesto por una escala Likert de 5 opciones.
Respondiendo directamente, se puede hacer pero yo no lo recomendaría a menos que ese ítem tenga varias opciones en una escala likert. Por otro lado, si el ítem es puramente cuantitativo (Por ejemplo: cantidad de horas trabajando) no habría ningún problema con ponerlo como variable dependiente.
Ojalá todo salga bien.
Muchos éxitos
LikeLike
HOla! Podrías hacer un post de regresión logística 😀 gracias!!!
LikeLike
Hola,
Muchas gracias por escribir a Stats SOS. Sí, quiero hacerme un tiempo para escribir un post sobre ello.
¡Muchas gracias por el pedido!
JC
LikeLike
Encontré el blog buscando información, y desde entonces no he parado de leerlo. Muchas gracias por la información práctica y amena en que lo presentas. Me quedé en una duda porqué el resultado de la regresión lineal simple coincide con el de la correlación de pearson en el ejemplo.
LikeLike
Estimado Brian,
Muchas gracias por escribir a Stats SOS. Me alegro mucho que el blog esté siendo de ayuda. Sobre tu consulta, está bien que coincidan dado que en un regresión lineal simple cuando se calcula el beta estandarizado se realiza el mismo procedimiento que si calcularas una correlación de Pearson. Ambos análisis tienen valores que van de 0 – 1. A su vez, estos dos análisis son bivariados (de dos variables). Es por ello que son equivalentes. Esta situación tan solo se da cuando es una regresión lineal simple, porque cuando comiences a hacer análisis con múltiples variables independientes (o predictores) como es el caso de la regresión lineal múltiple esta equivalencia ya no existe.
Mucho éxito y espero verte pronto por acá
LikeLike
Hola
Espero te encuentres bien. Encuentro tu pagina muy sencilla de entender y amigable y sobretodo de gran ayuda y personalizada. Te comento que en mi tesis obtuve distribuciones no normales y por lo tanto he aplicado estadísticas no parametricas. Parte de mis hipótesis apuntaban a explicar mi variable dependiente (cuantitativa) en función a 6 variables independientes (psicometricas también), es decir había planteado un análisis de regresión. Mi consulta es, para estas distribuciones no parametricas, qué tipo de regresión podría aplicar? Se podría hacer un análisis de regresión en todo caso? Podría hacerlo con el SPSS 21?
Agradezco de antemano tu apoyo,
Saludos,
Jose
LikeLike
Estimado Jose,
Muchas gracias por escribir a Stats SOS. Sí se podría hacer una regresión porque el supuesto plantea que la distribución de los errores (residuos) de las variables debe ser normal y no los puntajes.
¡Mucho éxito!
LikeLike
Estimado,
Muy genial tu blog, me es de gran ayuda. Al terminar de leer me quedo una duda. No me que queda claro como se explica que no exista diferencia en el resultado obtenido mediante regresión logística (tabla 3) y la correlación de pearson (tabla 4) ¿Por qué este valor es igual?
Saludos,
Constanza.
LikeLike
Estimada Constanza,
Muchas gracias por escribir a Stats SOS. Esta es una relación lineal y cuando la significancia es menor a 0.05 si es estadísticamente significativa. Por otro lado, salen igual porque en esencia la tabla 3 y la tabla 4 son el mismo análisis. La única diferencia es que en la tabla 3 se da el valor sin estandarizar y y en la 4 estandarizado.
Mucho éxito!
LikeLike
Hola Juan Carlos, espero que te encuentres bien, quisiera saber como es que puedo hacer una regresion lineal multiple si voy a realizar una encuesta con escala Likert para saber que variables son las que mas afectan en la rotacion del personal de una empresa, o como es que podria remplazar la escala Likert en mi cuestionario para que se pueda realizar la regresion.
Saludos.
LikeLike
Hola Jesus,
Muchas gracias por escribir a Stats SOS. Podrías usar tu escala likert y luego si todas las preguntas responden al mismo constructo entonces podrías sumar todas las preguntas.
Mucho éxito!
LikeLike
Hola Juan, gracias por tus buenas explicaciones, mi pregunta va en el siguiente sentido:
Si quiero hacer una regresión para ver la relación entre X y Y, en donde X es un constructo (con tres preguntas las tres en escala de Likert 7 niveles) y Y también es un constructo con 4 preguntas en escala de Likert 7 niveles, ¿cómo es que hago mi regresión entre estas dos variables X y Y? ¿por ejemplo haciendo regresión del promedio de X con el promedio de Y?
LikeLike
Hola! Tendrías que sumar o promediar esas preguntas para generar una sola variable X o Y y con ello podrías hacer tu regresión. Exitos!
LikeLike
Estimado Juan,
Tengo resultados de una encuesta, dada a N=100, pero los resultados son SI y No, como puedo aplicar regresión lineal con esos datos.
Agradecería me brindes apoyo a esa consulta.
Gracias
LikeLike
Hola Juan! No hay problema, si tu variable Y es cuantitativa y la variable X es Sí y No podrías aplicar una regresión lineal. Si tu variable Y es sí y no tendrías que aplicar una regresión logística. Éxitos!
LikeLike